2021.11.25
알고리즘 개요
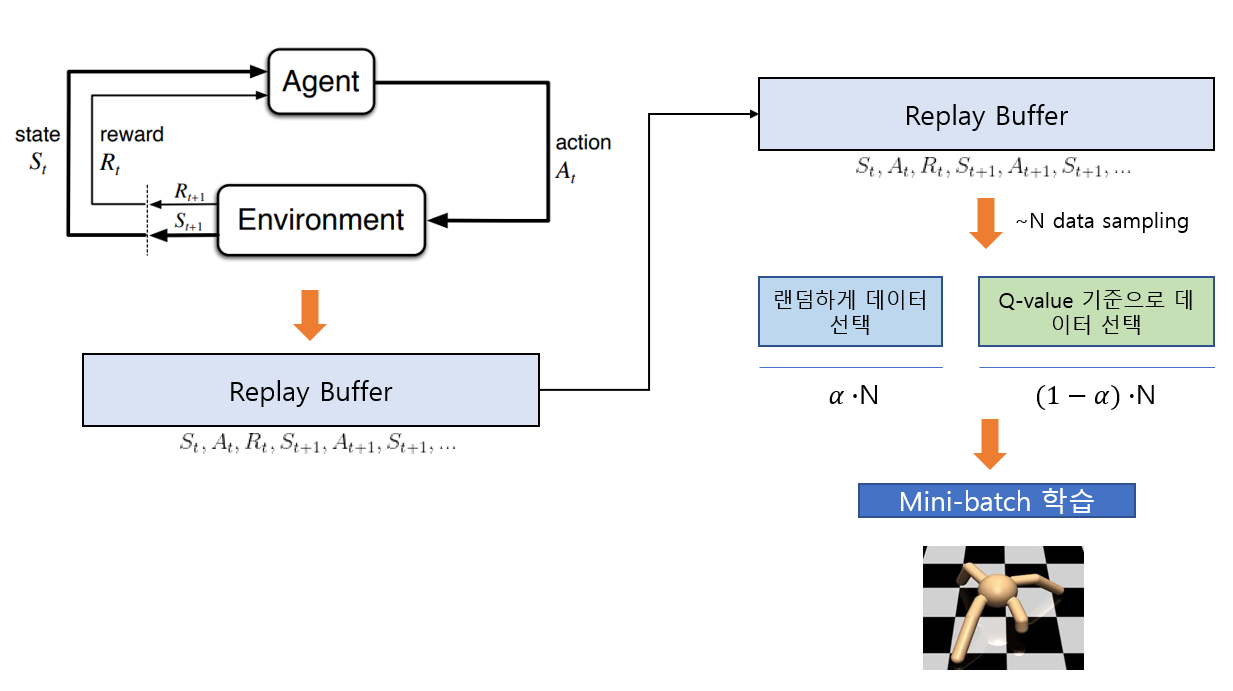
알고리즘의 큰 흐름은 다음과 같습니다. 먼저 일반적인 off-policy 알고리즘과 마찬가지로 에이전트와 환경과의 상호작용 정보(transition 정보)를 replay buffer에 저장합니다. 그 후 학습하는 과정에서 replay buffer에 들어있는 정보들을 Q-value가 큰 순서대로 정렬합니다. (시간복잡도: NlogN) 그 후 N개의 데이터를 골라 mini-batch update를 해줄 것입니다. N개의 데이터를 고를 때 먼저 alpha의 비율로 uniform random하게 데이터를 고른 후, 나머지 데이터들은 Q-value가 높거나 Q-value가 낮은 데이터를 고릅니다.
이 때 alpha의 비율로 uniform random하게 데이터를 고르는 이유는 Q-value만을 기준으로 데이터를 고르게 되면 correlation이 커지기 때문에 이를 줄이기 위함입니다. 그 후 나머지 데이터를 Q-value기준으로 뽑는 이유는 대부분의 transition 정보는 무의미하고 오직 소수의 정보만 유의미한데, Q-value의 크기와 데이터의 유의미성은 비례한다고 가정하였기 때문입니다.
의사 코드
새로운 알고리즘의 의사코드는 다음과 같습니다.

'일지' 카테고리의 다른 글
| 6. Q-value based PER 알고리즘 실험 결과 (0) | 2021.12.21 |
|---|---|
| 4. 새로운 연구 주제 설정 (0) | 2021.12.21 |
| 3. Active Reward Shaping 알고리즘 실행 결과 (0) | 2021.12.15 |
| 2. 알고리즘 구체화 (0) | 2021.12.07 |
| 1. 전체적인 연구 방향 및 목표 (0) | 2021.11.12 |



